Part 4 of “The Test Pyramid — Reimagined.” Start with the opener if you missed it.
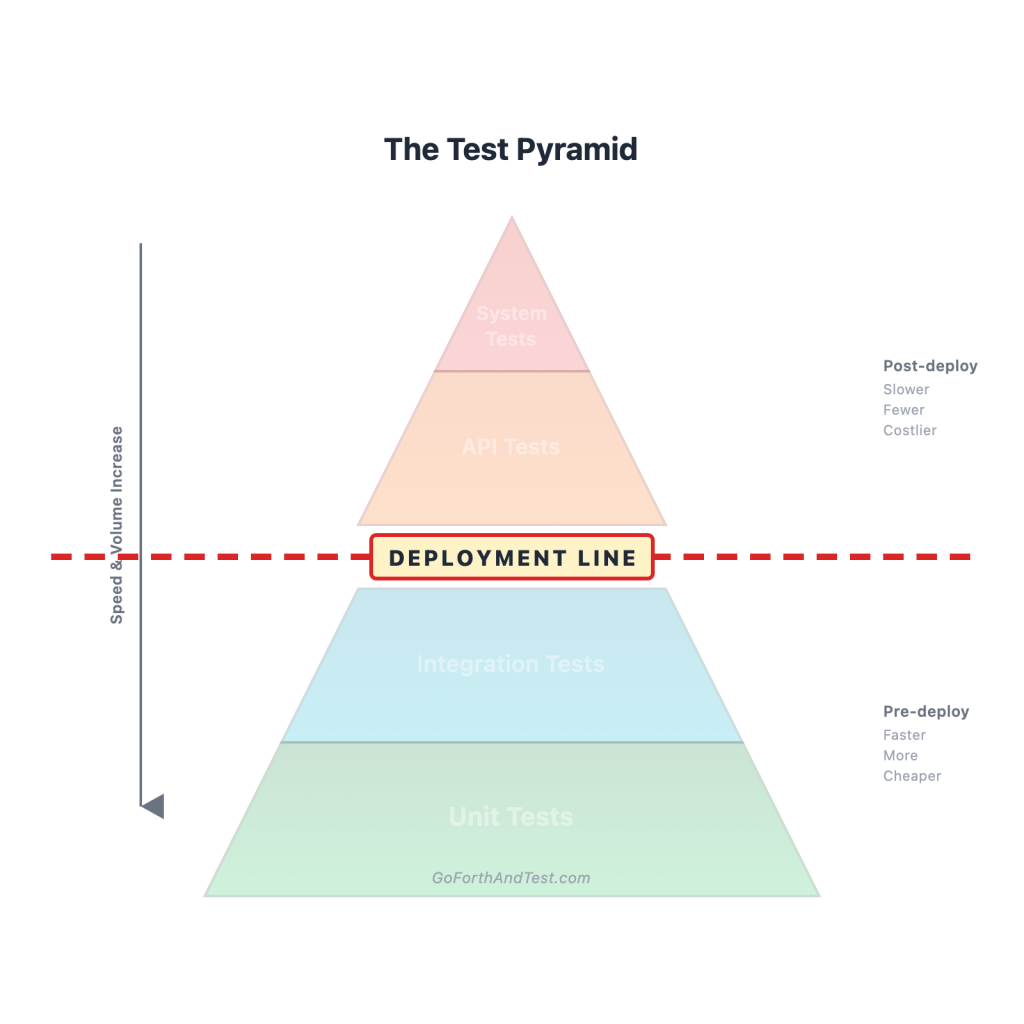
There is one line in your test diagram that separates the tests that cost almost nothing from the tests that cost almost everything. Most teams know this line exists. Almost no team draws it.
That’s the entire problem. The deployment line is one of those concepts that engineers are vaguely aware of — yeah, sure, some tests run before we deploy and some after, makes sense — and then they go right back to writing tests as if it didn’t matter, because nothing on the diagrams they were taught from prompts them to think about it. They don’t push tests below the line because they don’t see the line. They argue about test categories that the line would resolve in five minutes. They build sprawling, slow, post-deploy UI suites doing work that pre-deploy tests would have caught at one-tenth the cost, and they don’t notice they’ve done it because the cost they’re paying is invisible at the test level. It only shows up on aggregate, in CI bills, in engineer hours, in the time between commit and we know this works.
The deployment line needs to stop being a vague awareness and start being a front-of-mind decision. Every test you write, every PR you review, every test strategy meeting you sit in: which side of the line does this belong on, and why?
This post is about getting that question wired into your reflexes.
What the line is
I gave you the short version in the opener, and it’s worth quoting directly because it’s the load-bearing definition for everything else:
Everything above the line runs against a real, deployed environment. Everything below the line runs pre-merge, pre-deploy, on a developer’s laptop or a CI runner with no infrastructure to speak of. The line is not metaphorical. It is the literal moment your code stops being a thing in a pull request and starts being a thing on the internet.
That’s it. That’s the whole concept. There’s no clever machinery hiding underneath — it’s a literal, observable, infrastructural distinction about when a test runs in your release pipeline.
Below the line, your test runs against code that hasn’t been deployed yet. The code lives in a branch, in a container on a CI runner, in a developer’s local IDE. Nothing about your production environment is involved. No CDN. No DNS. No real auth provider. No third-party CSS. No load balancer. No real database, unless you’ve spun one up locally for the test.
Above the line, your test runs against code that has been deployed somewhere — staging, preview, production. All of those production-ish realities are present. Auth is real. The CDN is real. The downstream services are real. The deployment itself, with all of its config and its environment variables and its IAM roles, is real.
The transition between the two states is the deployment. That’s the line.
Why most teams are vaguely aware but never act on it
If you ask a senior engineer whether some tests are pre-deploy and some are post-deploy, you’ll get a nod and a “yeah, of course.” If you ask them how many tests are on each side of that boundary in their current suite, they probably don’t know. If you ask them whether any test in their suite should be on the other side of the line — should move from post-deploy to pre-deploy, or vice versa — you’ll usually get a long pause.
The pause is the entire problem.
The deployment line isn’t a missing concept; it’s a missing habit. Engineers are taught testing in terms of layers (unit, integration, e2e) and shapes (pyramid, trophy, honeycomb) and tools (JUnit, Playwright, Selenium). Almost nobody is taught testing in terms of when in the release pipeline the test runs, even though that’s the dimension with the biggest cost implications and the cleanest decision framework attached to it.
The cost cliff
Here’s the part nobody quantifies.
A pre-deploy test runs on every PR. It runs on your laptop while you’re writing the code. It runs in CI in seconds — maybe tens of seconds for a real integration test, but seconds, plural at most. It costs roughly the price of CPU minutes on whatever runner is hosting your CI. If the test fails, the developer who wrote the breaking code is sitting at their keyboard, with the change in their head, ready to fix it. The cost of finding the bug is minutes.
A post-deploy test runs after a deploy completes. Deploys are not free — they involve building artifacts, pushing to registries, rolling out to environments, waiting for health checks, sometimes waiting for traffic to drain. Even a fast deploy is a couple of minutes; a real one is fifteen, twenty, sometimes longer. The test itself runs against real infrastructure, which means it’s slower than a pre-deploy test even before you account for the deploy time. If the test fails, the deploy has already happened. The change is no longer in any one developer’s head; the team has moved on; somebody has to context-switch back into the breaking code and figure out what went wrong against a deployed environment, which is harder to debug than a local one. The cost of finding the bug isn’t minutes. It’s tens of minutes, sometimes hours, and that’s per failure.
It’s worth being concrete about that, because “engineer-hours” is easy to wave at and harder to feel. Most businesses have a number for what an engineer’s time actually costs — fully loaded, salary plus benefits plus overhead, typically somewhere in the $75 to $125 per hour range. Time isn’t a metaphor for money in this analysis. It’s a direct conversion.
A bug catches a bill at every stage it survives, and the bill goes up at every stage:
- Caught at PR time, fixed in minutes. Tens of dollars. The developer is still inside the change, the fix is small, and nothing else has happened yet.
- Caught post-merge but pre-deploy, fixed in QA. Hundreds of dollars — a few hours of dev time, plus the context-switch tax for whoever has to come back to the code, plus the QA cycle the bug just consumed. Cheaper than the next stage, but no longer free.
- Caught post-deploy by your team, requires rollback or hotfix. Even more hundreds per occurrence, plus team-wide disruption, plus the deploy you have to redo, plus the time everyone spends investigating the regression.
- Caught in production by a customer. Hundreds to thousands per incident, plus support load, plus reputational damage, plus — for the worst ones — somebody getting paged at 3 AM. The cost is no longer just engineer-hours; it’s the customer who didn’t renew, the trust you have to rebuild, the apology email someone has to write.
The deployment line is the cost cliff. Tests on one side are nearly free. Tests on the other side are expensive in ways that don’t show up on the test itself. They show up in the rest of the day, in the next sprint, and on next quarter’s invoices.
The push-down rule
Once you see the cost cliff, the strategy writes itself:
Every test you can move below the deployment line, you should.
Not “consider moving.” Should. Default to below. The burden of proof is on the test that wants to live above the line, not the other way around. If a test can be exercised pre-deploy — same coverage, same confidence — it has no business living post-deploy. The post-deploy slot is reserved for tests that can only run there, because what they’re testing only exists once code is deployed.
The corollary is even sharper. A test that lives above the line is paying rent for one specific reason: the thing it’s testing requires a deployed environment. Real auth tokens from a real identity provider. Real downstream services in a staging cluster. Real DNS, real CDN, real CSS, real third-party JavaScript. Real deploy mechanics — the IAM role that’s wrong in production but right in dev, the config value that doesn’t get injected when the container starts, the health check that flaps under real load.
If your post-deploy test isn’t testing one of those things, it’s a pre-deploy test wearing a costume. Demote it.
What “pre-deploy” actually means
There’s a wrinkle worth pulling out, because it confuses people: you can sometimes run an above-the-line test locally. Point your Playwright suite at localhost:3000. Build the mobile app on your laptop and run your Appium suite against the local build. That works, and it’s useful — it’s how you fix the test pre-merge when a code change breaks it, instead of pushing another commit later to clean up the test you broke.
But “I can run it on my laptop” is not the same as “it runs pre-deploy.” The deployment line is about where the test runs in the release pipeline, not about whether a developer can also run it on their machine. If the test runs in the merge-request pipeline — gating the merge, blocking the PR until it passes — it’s pre-deploy. If it can only run after the deploy completes, in a post-deploy job against a deployed environment, it’s post-deploy. That stays true even when a developer can also poke at it locally for debugging.
So the local-run trick is a developer-experience win, not a layer reclassification. Use it. It will save you a lot of embarrassing “oops, broke my own tests” follow-up commits. But don’t let it convince you that you’ve moved the test below the line. The pipeline decides that, not your laptop.
There’s a corollary worth saying out loud: the line is movable, deliberately. If you actually want to push a normally-above-the-line test below the line, you can — as long as you’re willing to make it run in the MR pipeline. For mobile, that means building the full app artifact in CI and running Appium against it before merge. Some teams do this. It’s a real option. The cost is a noticeably slower MR pipeline, paid by every PR, every time. Web is harder still: spinning up a full web app in a CI container with all its dependencies is doable (Docker Compose, ephemeral preview environments, CI services) but takes more plumbing and slows the pipeline further. Many teams correctly decide the cost isn’t worth it. Some teams correctly decide it is.
The point isn’t that the line is sacred. It’s that the line is real, and moving a test across it is a strategic decision with a recurring cost. Make the move when catching the bug pre-merge is worth that cost. Don’t make it because you didn’t realize you were paying a different cost on the other side.
The decision framework
When you’re staring at a test — writing it, reviewing it, inheriting it — there is exactly one question to ask:
Could this test run pre-deploy and produce the same result?
If yes: it belongs below the line. Move it. Now.
If no: ask what specifically requires the deployed environment. Be precise about it. “It hits a real database” is not a reason — Testcontainers exists, and your integration tests already use it. “It exercises the API” is not a reason either — your integration tests cover the API too, with the externals stubbed. “It needs the real auth flow” might be a real reason. “It depends on the CDN serving the right asset version” is definitely a real reason. “It validates that the deploy itself didn’t break anything” is the canonical reason.
The reason has to be specific. “That’s just where we put it” is not a reason; it’s a habit. Habits are what got the suite into its current shape. Replace the habit with the question.
The failure mode
What happens when teams don’t make this question reflexive is the inverted pyramid I called out in the opener: thin unit, almost no integration, hulking post-deploy UI suite. Every gap in the lower layers gets papered over with one more above-the-line test, because that’s where the tooling lives, that’s where the SDET sits, that’s where new tests have always gone.
The result is a suite that takes hours to run, fails for reasons nobody can diagnose, slows every release, and produces ambient distrust in the entire idea of automated testing. The team starts retrying flakes by default. The team starts ignoring failures. The team starts shipping without waiting for green builds, because waiting takes too long and the signal isn’t trustworthy anyway.
Front of mind
The deployment line is not a sophisticated concept. It requires no new tooling, no leadership buy-in, no re-architecture — just one question, asked reflexively, by every engineer writing or reviewing a test.
Which side of the line, and why?
Put it on a sticky note next to your monitor if you have to. The cost of asking the question is zero. The cost of not asking it shows up in your CI bill, your release cadence, your team’s morale, and the bug count that catches up with you about eighteen months in.
There is no other concept in test strategy that pays back this much for this little.
What’s next
Two posts left in the series, both above the line:
- API tests — the first thing above the line, useful when they earn it, and a costume worn by integration tests that escaped from below the line
- System tests — the apex layer, the one you should hate needing, and what it should and shouldn’t be carrying
Subscribe, RSS, bookmark — whatever your preferred mechanism is. The line is drawn. Now we deal with what’s left.
Discover more from Go Forth And Test
Subscribe to get the latest posts sent to your email.